
AI: Artificial Intelligence
Can you understand the things you observe and use them to make better decisions? Random colored dots that seem chaotic up close, when arranged by an artist in a pointillist painting, can become richly meaningful and appealing. The dots may have great variety in color and hue, and in the hand of the master painter, even the juxtaposition of two different colors may be a revelation. Sadly, even the most elegantly designed sequences of ones and zeros have little inherent meaning and no intentionality, but processed by digital computers and the people who use them, the digital information can come alive with usefulness, and meaningfulness.

Today, I would like to fill a palette with fresh colors, combining Artificial Intelligence (AI), Business Intelligence (BI), Natural Language (NL) and Machine Learning (ML), to show how they can tame digital chaos, find hidden order, and help people make better decisions. The CI in the title can stand Competitive Intelligence or Continuous Improvement (or 226 other possible meanings). Whichever, most companies regularly need to make better decisions in multiple disciplines to increase value, and better compete in a crowded free market economy. This can be achieved by giving more corporate citizens actionable information. Shifting the balance in decision making to put more burden on the machine, and the formal model upon which the decision is based, will empower people across the spectrum to improve outcomes.
Information as Evidence

Dr. David Sackett, McMaster University in Ontario, Canada, defined evidence-based medicine as “the conscientious, explicit and judicious use of current best evidence in making decisions about the care of individual patients” (Harvard Business Review, January 2006). If evidence is better for medical decisions and education, might it not be valuable wherever complexity challenges decision makers? Yes! The more factors that influence a desired outcome, the more evidence about the factors and their mutual impacts is needed to:
- reduce risk of adverse consequences/ripple effect, and
- increase probability of favorable outcomes.
According to the Harvard Business Review article, “Recent studies show that only about 15% of their decisions are evidence based”. What do people use to make decisions?
- obsolete knowledge gained in school (sometimes antiseptic),
- long-standing but never proven traditions (dogma and belief),
- patterns gleaned from experience (one person’s perspective),
- methods they believe in and are most skilled in applying (one person’s competence), and
- information from hordes of vendors with products and services to sell (HBR 2006)
Have things changed much since this was published? You decide. Building an “evidence-based knowledge culture” implies that business decisions are more frequently based on smart humans spending more time exploring possible scenarios, and collaborating with other smart people to cross-pollinate ideas, because they are not spending all their time fighting with incomplete, incorrect and disjoint data. How can we change this and improve decision-making processes?
- Architects engineer the platforms / frameworks that accelerate the rise of the Citizen Data Scientist.
- These are SMEs in every area of the company — including IT.
- Crowd-sourcing is needed for a rising tide instead of peaks and valleys of good decisions
- IT fundamentally changes its focus toward empowering SMEs.
- Less commoditized IT— maintenance work that looks roughly the same at every company.
- More differentiated work — Enabling IT to become a direct provider of business value.

The importance of increasing evidence-based management has prompted the formation of a new non-profit foundation to help managers use information more effectively: the Center for Evidence-Based Management (CEBMa). There is also a related book called “Evidence-Based Management: How to Use Evidence to Make Better Organizational Decisions”. According to the foundation, “The starting point for evidence-based management is that management decisions should be based on a combination of critical thinking and the best available evidence. And by ‘evidence’, we mean information, facts or data supporting (or contradicting) a claim, assumption or hypothesis” (CEBMa FAQ). Sources, they suggest, may be scientific research, internal business information and professional experience, though some of that may be double-edged, as indicated in item 3 above from the HBR article. The key point is for more managers to base their decisions on more evidence.
The evidence needed includes digital information such as facts or data in databases and literature (unstructured information from documents and web content) representing experts’ “values and concerns”, including assumptions or hypotheses regarding what, why, how, when and where factors influence the outcomes of specific decisions. This can constitute massive quantities of information, some very fuzzy, of varying reliability and relevance.
Much of the differentiated work IT can do to better support these processes is to get the relevant structured and unstructured information to the subject matter experts as efficiently and meaningfully as possible, scoring the reliability and relevance of each input. This scoring process, especially when automated, may be part of an “explanation utility“, long considered a key component of AI and Case-Based Reasoning systems.
Pathways to Decision
There are many ways to get to a decision. Humans constantly make decisions from choosing a career or spouse to deciding where to place a footfall to avoid an obstacle. The human brain, a network of interconnected neurons used both to store and process information, is able to make many of these decisions instantaneously. Sometimes we agonize forever over more complex decisions (Hamlet). More and more, humans are relying on computer algorithms to assemble the needed evidence to aid in decisions. And the algorithms and platforms themselves are becoming smarter, reducing the amount of human effort to arrive at defensible decisions.
We can shift more of the “due diligence” on important decisions to computers, and doing so can:
- reduce risk,
- improve the speed to decision, and
- improve the quality of the outcomes.
The quality of the model is critical to achieving these improvements, so I’ll address that specifically below. Machine decision flow may be designed to mimic human decision making.
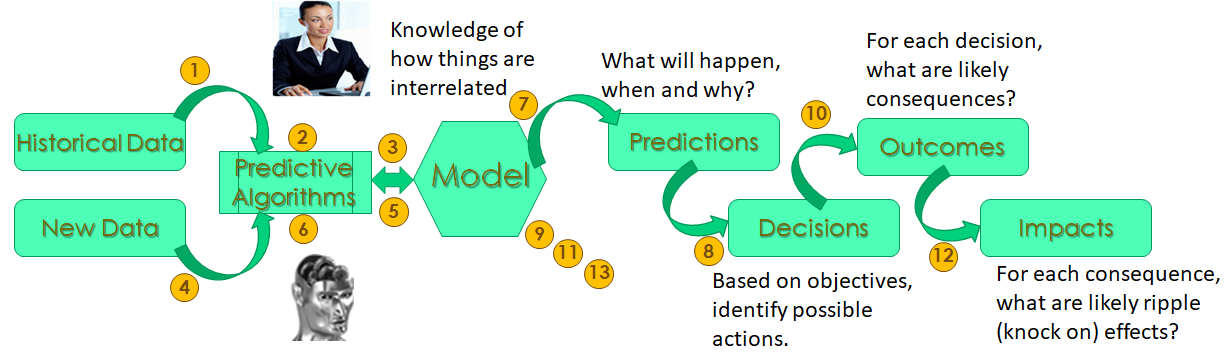
It is not an accident that the process touches the model at 3, 5, 7, 9, 11 and 13. The predictive algorithms may be based on a variety of strategies. Earlier, I mentioned Case-Based Reasoning (CBR) which is a common Machine Learning (ML) strategy. Alternatives include Naive Bayes classifiers, Genetic Algorithms and traditional Neural models. Each have different strengths in finding and “learning” patterns that predict behaviors and outcomes. Building good case-based models requires decomposing the problem to its constraints (or decision factors) and representing them in a way that supports efficient resolution. Selection of the learning algorithm may affect the speed and acuity with which patterns are identified and learned, and the clarity with which they are reported.
For decision support with explanation, natural language-based models provide a familiar interface for users with less technical skills, and make it possible for Subject Matter Experts (SMEs) to curate both the content and the models. SME curation is possible with CBR, Bayes and Genetic approaches, but not so much with agnostic Neural models. To make it efficient or even possible for SMEs to perform curation and model management, simple workflows and tools are needed. This is especially important to reduce the amount of training to a manageable level for non-technical SMEs (citizens) to perform model management.
Information is a company’s greatest asset

We have a clear sense of the general value of information. We spend millions to gather, manipulate, store and examine it, but … most organizations do not know the value of most of the information they have. The problem is exacerbated by the growing volume of varied information, and the velocity with which it is expanding. They know that they can often use information to gain competitive advantage, but … they do not yet know how each database, document, video, image, and audio file can help. They might not even know where to find them, or how to deliver them to improve decisions: they lack sufficient metadata, and ways to efficiently manage and exploit it. Many organizations have no models describing meaning and intent needed to automatically categorize and exploit information and support AI and ML.
Knowledge about data, Metadata, can become Metaknowledge in four steps:
- Establish and maintain a robust enterprise information model
- Classify all information assets in a single metadata repository
- Establish a controlled vocabulary with KPIs, formulas and definitions
- Use these to architect a “Knowledge Framework” for AI and ML to improve search, BI, Analytics and DECISIONS
This work is often – no, usually – too complex and time-consuming for most organizations to do it. They would need to hire separate people with specialized skills that are not widely available. Alternatively, they would need to automate items 1 and 2 with AI.
Commonality in All Information

Whether structured or unstructured, including rich media, and no matter the subject, all information has Meaning. Structured data in databases is usually more straightforward and easy to interpret. Unstructured, less so. In a report today, I heard a Marketplace Morning reporter describe how the JOLTs job openings report may overstate the reality of employment opportunities in the United States. The meaning may be accurate – that the number reflects actual job postings – but the inferred intent, that there are that many open positions in companies, may differ because some job postings are not intended for immediate hiring, some are not full-time, some are intended for exploratory purposes, and so on. Meaning may represent intent, or it may obscure it. The difference between JOLTs jobs number and reality may not matter if the non-jobs represented are not statistically significant, or if the users of the report factor the difference into their calculations automatically.
All conversations have utterances, each of which originates from a person with Intent. Decisions and intent / intentionality are inextricably linked. Intentionality is the formal link between intent and natural language. To get to intent, you almost always have to go through natural language to first understand the meaning. While meaning is inherent in the words and can be automatically interpreted with NLP, determining intent may require the ability to process idioms, metaphor, subtext and other exformation. Humans identify idioms, metaphor, subtext and other exformation based on context and knowledge of the speaker or writer. I believe machine intelligence can be elevated to do this using robust models of communication behaviors.
Most intent models represent straightforward meaning, and attempt to infer intent from words based on natural language understanding or statistical models. The more statistical models are used, the less likely the system will be able to discover the true intent. This is because intent is based in the mind of the originator, but the words’ inherent meaning may not represent the intent, due to metaphor, sarcasm, irony, deception and other subtext. Today’s AI is still struggling to accurately interpret straightforward intent, and very little is being done to go deeper into natural language understanding to really understand people’s motivation and the deeper context of what they say or write.
Where the Meaning Hides
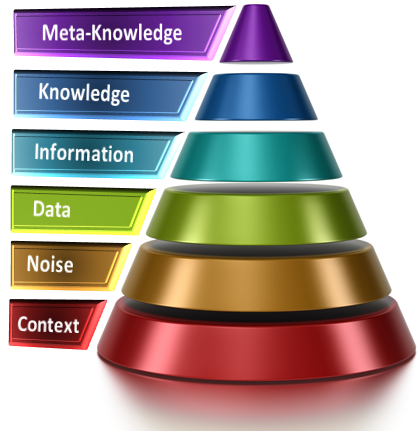
Meta-knowledge is a model that describes context, and can be used to automatically infer meaning and intent. Knowledge and language (a framework of meaning) may be even more complex than meets the eye. Notice that in this model of all information, noise is part of context – this is critical to good filtering. Unclean data drags the content toward noise. Good meta-models and heuristics can elevate the content and outputs toward actionable knowledge. Current tools and techniques work with Data and Information, and are straining to reach the level of Knowledge: i.e. actionable information. To automatically derive meaningful and actionable information, systems can use AI-based heuristics with meta-knowledge.
The human brain is both the model and the processing mechanism – all in one. The network of neurons and the connections between them represent the knowledge objects and their associations. The flow of electrical impulses processes inputs and outputs. This is where and how intent is translated into words, and similar processes in reverse are used to decipher the intentionality in others’ words (i.e. understand). The components of a digital model may include:
- Knowledge Network (graph) → Ontologies or Bayesian Networks describe concepts
- Metadata Repository → End disjointedness with a single big table for all assets
- Controlled Vocabulary → Build consistency with definitions, formulas and lineage
- Discovery Bots → Building and maintaining it is too much for humans
- Curating/Validating Tools → Bots’ automated inferences may need to be tweaked
- Machine Learning → Anomalies and ambiguities need not repeatedly offend
- Supervision Tools → ML inferences may need to corrected, rejected or reinforced

The model is semantic, and represents meaning in an interconnected network of domains, categories and concepts. The tools described above are used to build and maintain the model. A common framework for models is to build an ontology based on Resource Description Framework (RDF) or Web Ontology Language (OWL). The model strategy I prefer is more complex than OWL/RDF, and yet simpler. OWL/RDF is based on URLs, each of which represents a node in the network. My preferred framework is a fuzzy Bayesian Network where each ontology node is a weighted knowledge proposition described in ordinary words. The weighting permits fuzzy reasoning. Each connection between two knowledge propositions is based on the words that describe the associated concepts.
This model was designed to support fully automated natural language interpretation and translation. Interpretation and translation (of a sort) are extremely helpful in both building and exploiting the model.
Exploiting the model may use some of the same tools used to build and manage the model (ontology), but the processes are likely to differ in significant ways. Here are some tools to exploit the model to support better decisions.
- Heuristics → any practical method to problem solving, learning, or discovery not optimal or but sufficient to reach a goal
- Inference Engine
- Forward chaining → When rules are complex but branching is known a-priori
- Backward chaining → When path is not known but rules are known or discoverable
- Neural Network → Low-dimensional problems with dirty or inconsistent data
- Bayesian Network → For graph-type information spaces with many nodes
- Hidden Markov Model → For problems where evolving facts could change outcome
- Genetic Algorithm → For complex problems where ambiguity impacts process
BI: Business Intelligence
In my last post I described BI and what is the meaning of “insight”. According to Merriam-Webster, insight means:
- the power or act of seeing into a situation : penetration
- the act or result of apprehending the inner nature of things or of seeing intuitively
The words “seeing” and “apprehending” in these definitions seem to indicate human cognitive processes, and rightfully so. It is not common for us to think of insight as something you would leave entirely to a computer or its software: there is almost always a human involved in processing insights and using them to make better decisions. Insight should not confused with visualization:
- the representation of an object, situation, or set of information as a chart or other image
- the formation of a mental image of something
Given a set of inputs…
- Visualization is a graphical representation of some fact or set of facts
- It must be analyzed by a human with the gifts of sight and intelligence
- Insight is the “meaningful” result of application of intelligence (human and/or machine)
- Competitive Intelligence is insight that is directly applicable to making better decisions
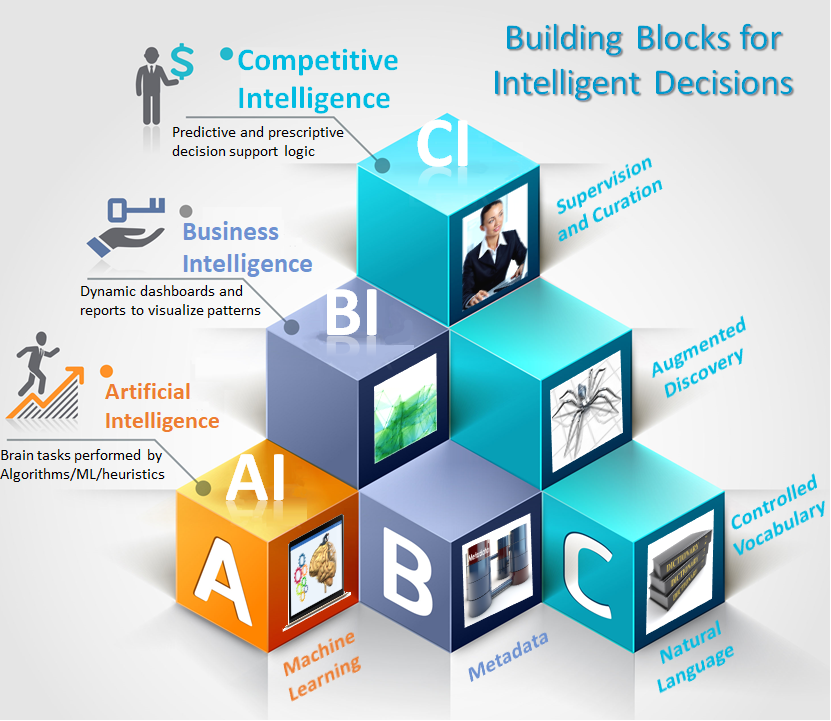
The picture suggests that the foundation of better Business Intelligence and competitive intelligence is better AI and machine learning, and better metadata and natural language (semantic) capabilities. This is the best architecture, in my view, for making decisions more science and less intuition. Intuition is good and important. It works much better when informed by solid science.
Quantitative vs. Qualitative Information
I have already referred to unstructured data in this post. Consider it’s implications for business intelligence. Quantitative information is more measurable and likely to tell us what happened (output/narrow outcome), when and where? Qualitative information is more fuzzy and could tell us why, what are the broader outcomes and what might happen next? Examples might be as follows:
Weather,Regional daily temperature was 5% higher than the 50 year average,Nighttime cloud cover; ozone depletion; soil heat retention and warmer convection raised temperatures
Sales: US Sales increased by 3.6% compared to 4.2% increase in the prior year, Competing products with new features and market uncertainty impaired US sales growth in the quarter
Election:12% more women voted for this party in this race than in the last election, More women candidates on the ballot and high profile appearances from female advocates improved turnout
Process Plant efficiency improved as shown by 31% increased throughput, Lean manufacturing improvements reduced WIP at three critical points in the Plant 3 assembly line
State of the Art in Insight

Again, organizations invest huge sums to acquire, manage and exploit data. The challenges are both in IT that provides the platforms and moves the data, and in the users who most need to gain the insights. In a recent Gartner report, Cindy Howson said: “Self-service analytics sounds empowering, but without the right skills distributed across the business and outside of IT, self-service can simply be overwhelming and lead to chaos. In addition, data that can yield new insights has exploded, but organizations are barely good at mining even transactional ERP data.” The videos on this McKinsey Digital page speak to the challenges. The process most commonly in use today involves data, analytics tools, and human interpretation:
Get data → Pass through machine → Think about it → Derive questions and answers
The challenges with this approach are associated with both the tools and the people who wield them:
- The BI design is based on incorrect or weak assumptions (model)
- Inconsistent data quality skews the answers or reduces the sample size
- Inconsistent skills in data preparation and exploitation lead to inconsistent evidence
- Inconsistent results arise from decisions made with evidence that is suspect
I propose that to overcome these options, organizations could:
- Improve assumptions (build and manage a better model)
- Reduce disjointedness (use the model as a basis for mastering/cleansing data)
- Automate more (Reduce error-prone manual steps)
- Use Brain-like methods (use the model as the basis for processes and vice-versa)
The building blocks I showed above, especially incorporating natural language to derive intent from information, provide the platform for better model-based decision making. The predictive analytics cycle is based on those building blocks, and returns to the model at every step. Intertwining the process and the model is consistent with human reasoning processes.
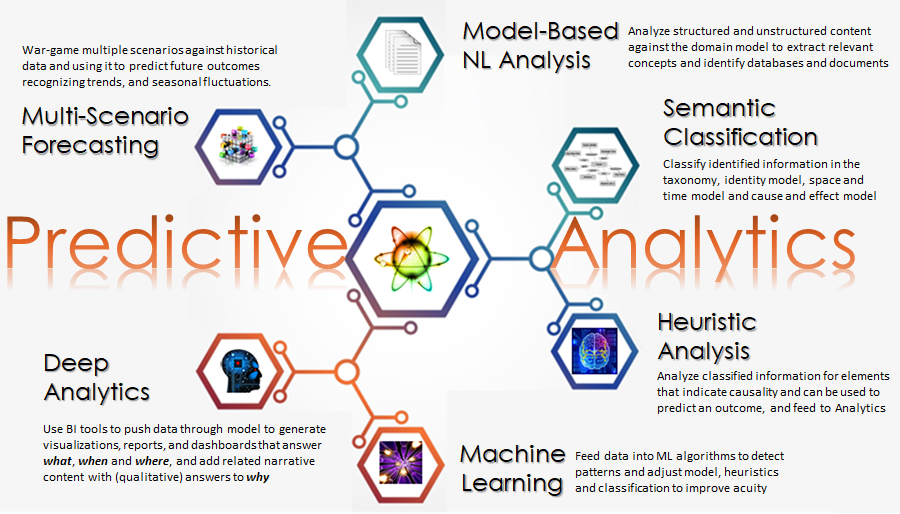
I haven’t said much about working with scenarios in this blog or this post, but they are very important. And the more permutations that are explored and added to the model, the richer and more reliable the predictions and prescriptions can become. Consider the fascinating story of weather observations and advanced scenario modeling in “The Coming Storm” by Michael Lewis. His observations about making the prescriptions palatable to make them easier to follow and harder to ignore show important insight into human psychology.
The prescriptive analytics cycle adds a few steps after forecasting:
- identify and prioritize possible actions that could lead to positive outcomes and rate probabilities
- push the actions through the model to identify risks and possible peripheral consequences
- Present to SMEs and collaboratively validate and reprioritize actions based on analyses
These steps imply that the model contains robust patterns showing causes and correlations of desired outcomes, including those provided by SMEs and those discovered through data mining and machine learning. It also implies risks are in the model tied to causal factors. The more robust the intent model, the better the system will be able to represent scenarios and prescribe actions.
